What Butterfly Is This?
An explanation of how I built a mobile application that classifies photos of butterflies and moths into 100 different species, using the power of Artificial Intelligence.
Table of Contents
Motivation
This project was developed to serve as final work for the course Advanced Computational Techniques for Big Imaging and Signal Data, in the second semester of my Master’s Degree in Artificial Intelligence for Science and Technology at University of Milano-Bicocca.
Overview
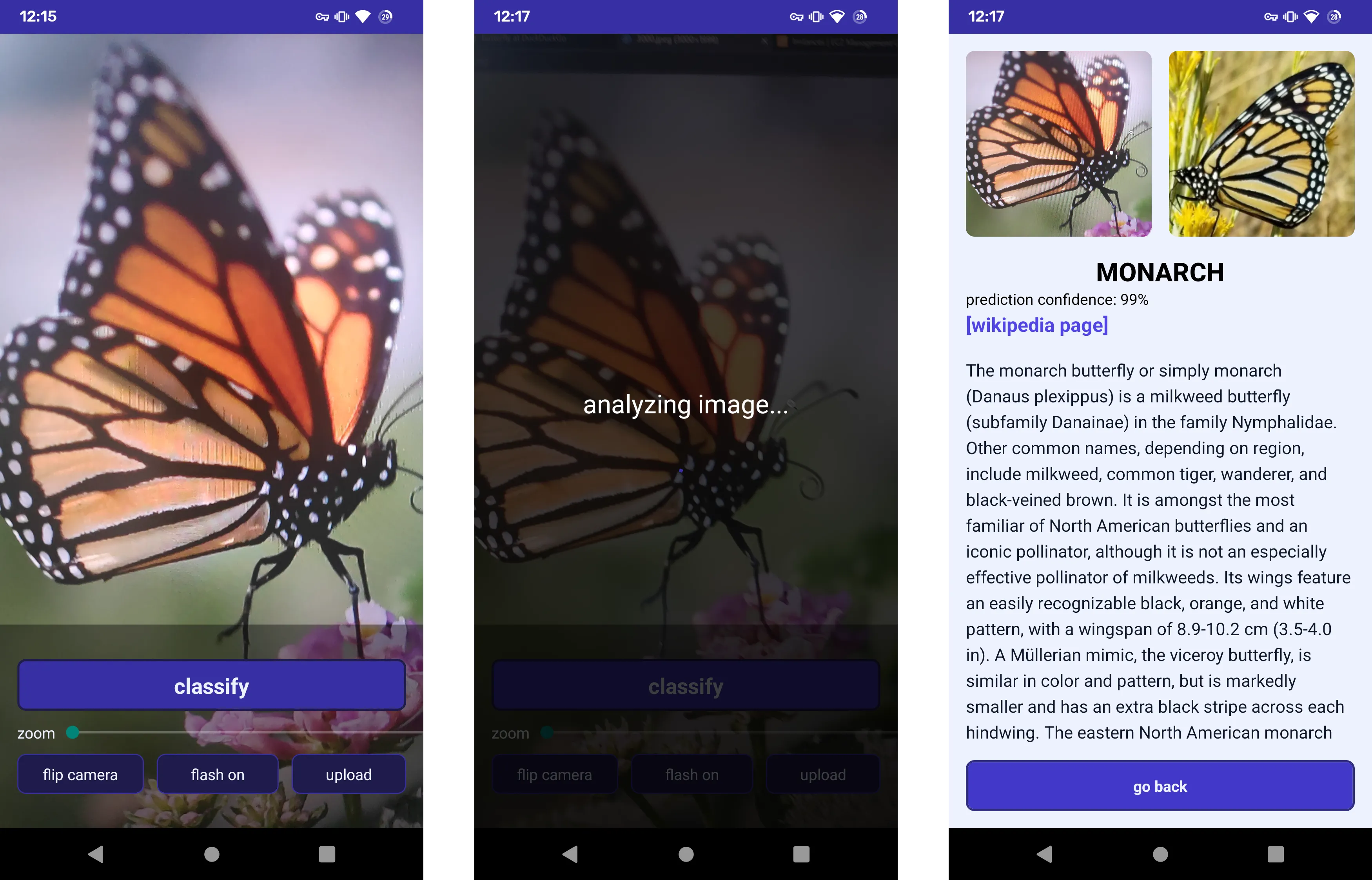
Upon opening the app a view of the camera feed is shown, with the option to take a picture or upload one from the phone’s gallery.
After the analysis is complete a page containing the results appears containing the species name, a brief description, a reference photo and a link to the wikipedia article.
In addition, the confidence of the prediction is also shown, to give the user more information.
Machine Learning Model
Below I first talk about the datasets used, then move to the model architectures and training procedure and finally to the evaluation of the performances.
To implement the models and train them I used the PyTorch library.
Dataset
The data for this project can be found on kaggle.com, and is composed by a main dataset of around 13k images of butterflies and moths, equally split into 100 classes.
Since there was no class without any butterfly or moth I had to create it myself, by merging it together with a sample of two smaller datasets, one with other insects and the last with just leaves.
- insects: kaggle.com/datasets/hammaadali/insects-recognition
- leaves: kaggle.com/datasets/alexo98/leaf-detection
All these images are 224x224 pixels in size and have 3 color channels (RGB).
Model Architectures
Being a computer vision problem I chose to employ two of the most famous architectures in this field: ResNet(2015) and Swin Transformers(2021).
The residual connections in ResNet models allow for very deep networks while mantaining low complexity, making them ideal to handle a high number of classes. More specifically I trained ResNet18, ResNet50 and ResNet152 models, where the number represents the number of layers.
On the other hand, Shifted Windows Vision Transformers are a more efficient version of the original Vision Transformer(2020) since they limit self-attention computation to non-overlapping local windows while also allowing for cross-window connection. In this case, the implementations I chose are Swin-t, Swin-s and Swin-b.

Training Procedure
During training the dataset is augmented by having a random change of horizontally flipping or rotating each image. By doing so the model should learn to be invariant to this kind of transformations.

Finally, to reach better results I started from checkpoints pretrained and fine-tuned them on the dataset. The pretraining was done on the ImageNet dataset, a large visual database of more than 14 million images making up more than 20,000 categories.
Performance Evalutation
After all models were done training I wanted to determine which was the best for my use-case. Since the product is a mobile application on top of a high classification accuracy I was looking for high inference speed with the goal of having the best user experience possible by reducing the loading times.
By plotting the accuracy with respect to the CPU inference speed we can see that the optimal model is ResNet18.

Measuring ResNet18’s performance on the test set (1.3k images) we reach the values reported in the table below.
| accuracy | precision | recall |
|---|---|---|
| 93.02% | 93.25% | 93.25% |
Mobile Application
The mobile application was developed with React Native through the Expo framework, so that it can be compiled for both Android and iOS while keeping a single codebase.
The image, after being taken, is sent to a Python server written in Flask which takes it and runs the inference to get the predicted class. This server was deployed on the AWS Elastic Cloud Compute (EC2) service.